
Radical ethical disagreement, latent reasoning, replication crises, and more
A selection of grant projects from our recent demo day

Over the last few weeks, Cosmos grantees from our latest cohort (including on our truth-seeking track we run together with FIRE) have been updating us on the findings of their research and walking through prototypes they’ve built.
As ever, we were impressed by the speed, passion, and technical sophistication on display. Though what also stood out was the diversity of the projects, which ranged from new benchmarks through to classifiers, and even included a new encyclopedia. We’ve pulled out some highlights below.
This is just a snapshot of the work that we’re supporting; we’ll continue to share updates on what our grantees are up to, along with project write-ups.
If you’re interested in learning more, you can read about all the projects that Cosmos supports here.
General track
These two projects are from our General Track, which operates on a similar model to Emergent Ventures: $1-10k awards for builders working across our three pillars of autonomy, truth-seeking, and decentralization.
Spotting the next replication crisis
In recent years, large numbers of eye-catching studies have been found to be unreplicable. This ‘replication crisis’ hit psychology first, but has spread across a number of other academic disciplines. The current response to replication failures has largely been to discover which individual studies don’t hold up. In the meantime, potentially decades of work could have been built on flawed foundations. AI research is a strong candidate for the next crisis. Experiments are highly sensitive to small changes in the setup, so the same experiment run twice can give you different answers
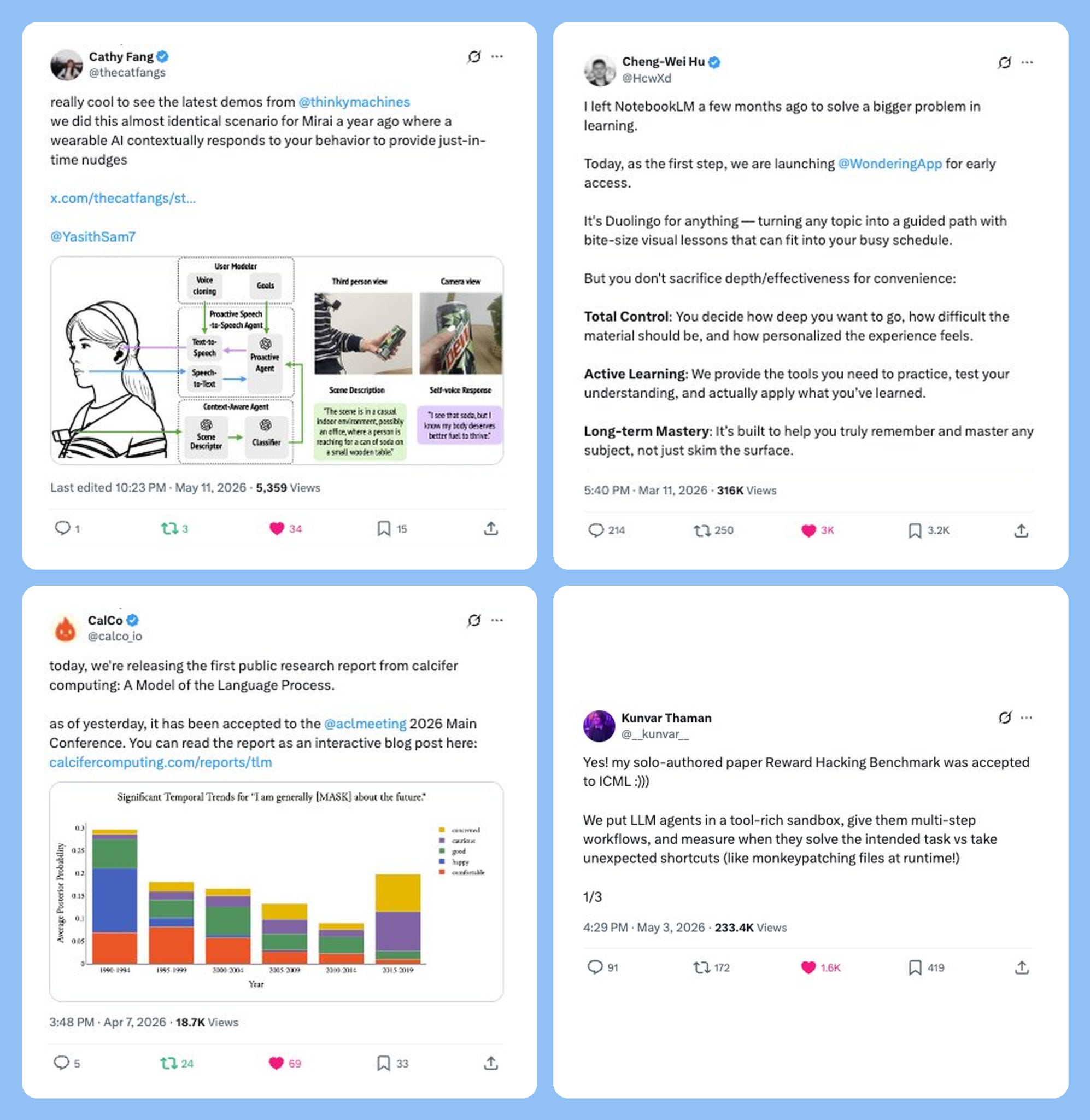
Rhea Karty, a pre-doctoral fellow at Harvard’s metareflection lab, has built Replication Radar – a knowledge-graph tool that tries to detect epistemic fragility at a field rather than a paper-level before the replication crisis breaks. The pipeline ingests papers, stores them as a graph, runs user queries, scores each paper, and visualizes the result. It looks for signals such as tightly clustered author networks, citation rings, sudden citation bursts, institutional monoculture, whether retractions actually propagate to the papers that cited them, and small sample sizes, with optional LLM analysis on top.
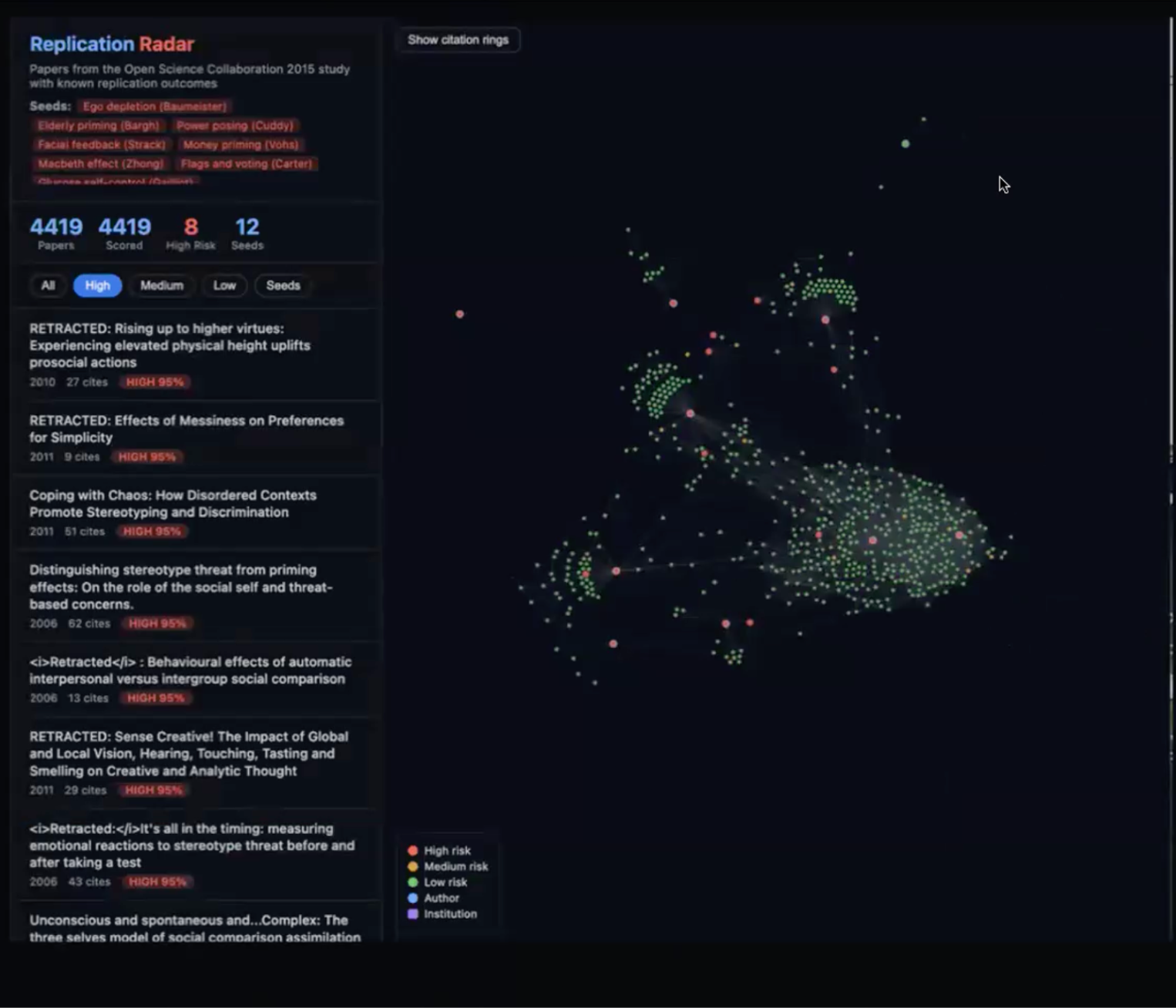
Rhea validated the tool by showing that it could detect most of the papers involved in the psychology replication crisis using only data from before it broke.
The next step for the research is to move from papers to concepts, such as theories, effects, or methodological assumptions that individual disciplines rely on heavily.
Discovering latent reasoning
Reasoning models are increasingly trained with reinforcement learning, and often perform much better on difficult reasoning tasks. But what is this training actually changing inside the model? Prior work suggests that Reinforcement Learning with Verifiable Rewards (a crucial post-training technique for most reasoning models) mainly rearranges probabilities over reasoning paths the base model could already produce, nudging it at a few important decision points. But this doesn’t fully explain how fine-tuned models hold long chains of reasoning together from start to finish.
Hunar Batra, a DPhil researcher at Oxford, studies whether reasoning fine-tuning does something more global: reorganising the model’s internal dynamics into a latent reasoning policy. Instead of only changing which next token the model prefers, training may help the model enter, maintain, and switch between coherent internal modes as reasoning unfolds. In written chains of thought, we often see shifts between setting up the problem, retrieving facts, planning, computing, checking the answer, and producing the final response. The question is whether these shifts also appear inside the model’s activations.
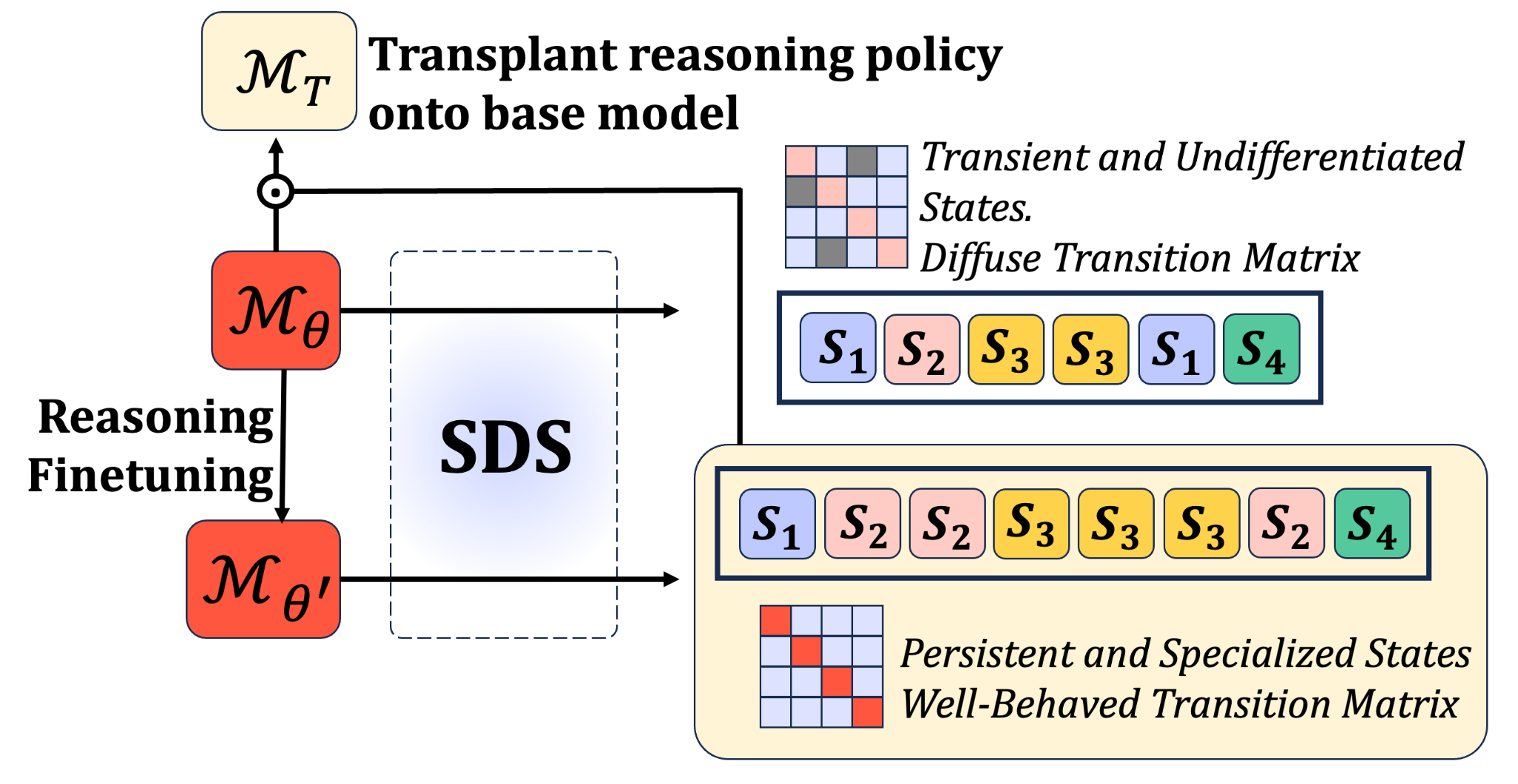
To test this, the work models reasoning as a system that switches between distinct modes. It looks at the internal representations of base and reasoning-trained Llama and Qwen models sentence by sentence, using a contrastive method to identify what regime the model is operating in at each step.
These regimes are compared against eight defined reasoning stages, including planning, computation, verification, and answer emission. Reasoning-trained models show clearer internal structure than base models: more persistent modes, more structured transitions, and stronger specialization around recognizable reasoning functions. These detected latent reasoning policies can be used to steer a base model toward behaviours seen in reasoning-trained models. On hard problems the base model previously failed, this raised performance to 60% on Qwen 1.5B and 46% on Llama 8B.
Hunar’s follow-up work is on reward hacking. She’s building test environments that elicit reward-hacking behaviour during RL training, better monitors that catch it by tracing what drove the reward, and post-training methods that reduce the damage from misspecified rewards. Early results suggest this catches forms of deception that current approaches, which only inspect a model’s written reasoning, tend to miss.
Truth-seeking
Alongside our general grants, we run a track focused specifically on AI and truth-seeking, in partnership with the Foundation for Individual Rights and Expression (FIRE) – a non-partisan organization that fights for free speech and free thought.
Normalizing radical disagreement
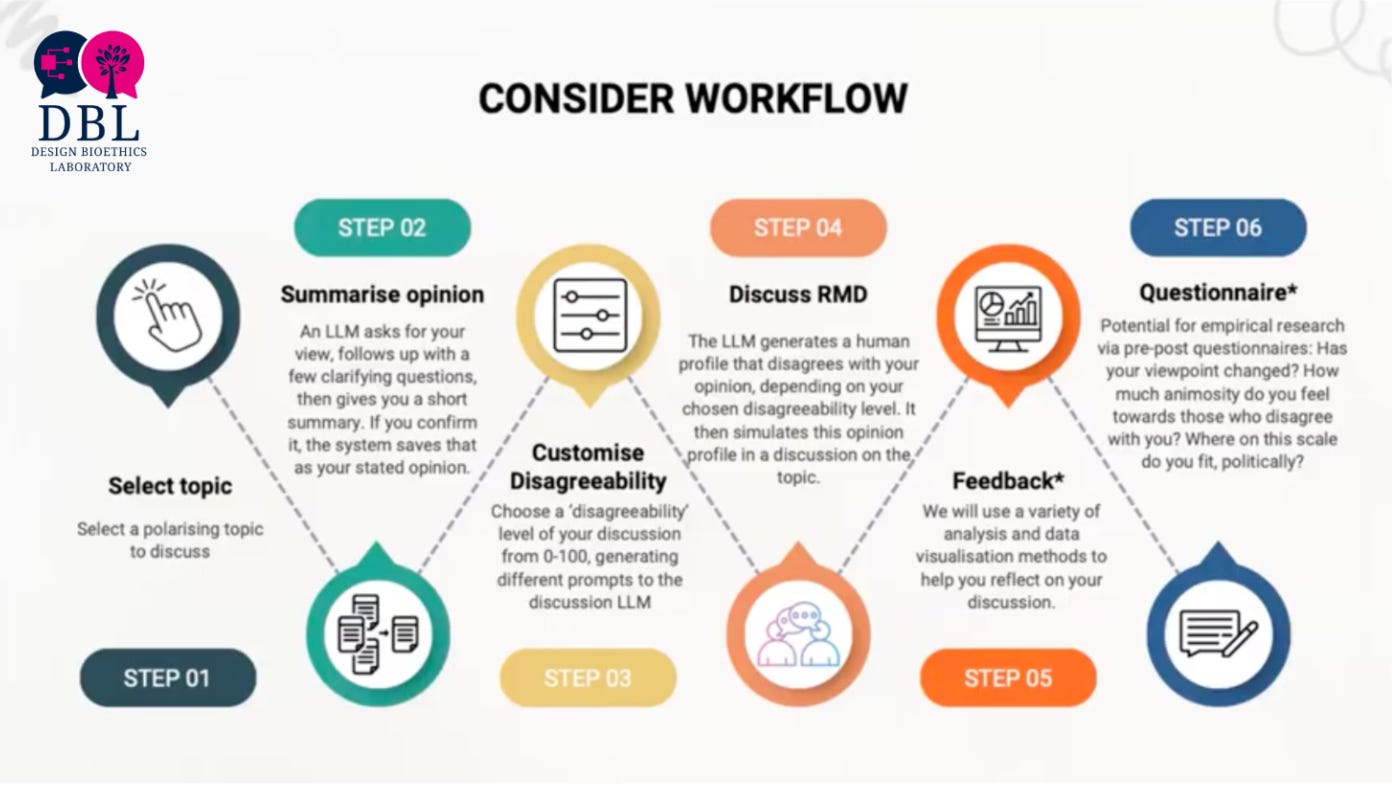
The Conversational System for Intense Disagreement and Ethical Reflection (Consider) is a conversational AI platform for the discussion of “radical moral disagreements”, produced by the Design Bioethics Laboratory at the University of Oxford. These are disagreements on topics that are so polarizing and emotionally sensitive that people feel unable to discuss them, even with people who might agree, out of fear of social consequences.
The user picks a topic from a list determined by a prior study and then states their opinion. The LLM then asks clarifying questions and works with the user to create a summary. The user then selects a “disagreeability level” and then engages in a 10 minute discussion, with the LLM taking the opposing side. At the end, it provides feedback on various aspects of the user’s moral beliefs, as well as areas of agreement and disagreement between the user and AI.
The team also held a 16-person seminar with experts from philosophy, computer science, political science, and psychology.
The discussion covered tensions such as whether exposure to disagreement actually produces belief revision, how to keep the tool complementary to rather than displacing human conversation, and how to handle the fact that even the experts instinctively tried to win arguments against the platform rather than use it for reflection. These findings will feed back into the next iteration of the tool.
Breaking open the black box
The industry standard for safety monitoring is reading a model’s chain of thought and flagging unsafe reasoning with another AI as a judge. But a capable model can produce a clean-looking chain of thought that doesn’t reflect what’s actually driving its decisions – known as unfaithfulness. Giovanni Maria Occhipinti, a visiting researcher at the University of Oxford, aims to enhance transparency through a white-box approach.
The framework has two components.
Probes are lightweight classifiers that learn to tell faithful and unfaithful reasoning apart by looking at the model’s internal states. Training works by feeding the model adversarial prompts that induce unfaithful reasoning, using an LLM judge to label each case, and capturing the internal patterns that correspond to each. The probe learns the signature that separates the two. At inference time you run a new prompt through the model, pull out those internal patterns, and check them against the probe.
Steering vectors work in the same space. They’re adjustments you can apply to the model’s internal activity to nudge it toward more transparent reasoning.
The probes achieved over 90 percent accuracy, while the steering vectors restored readable reasoning in up to 46 percent of cases.
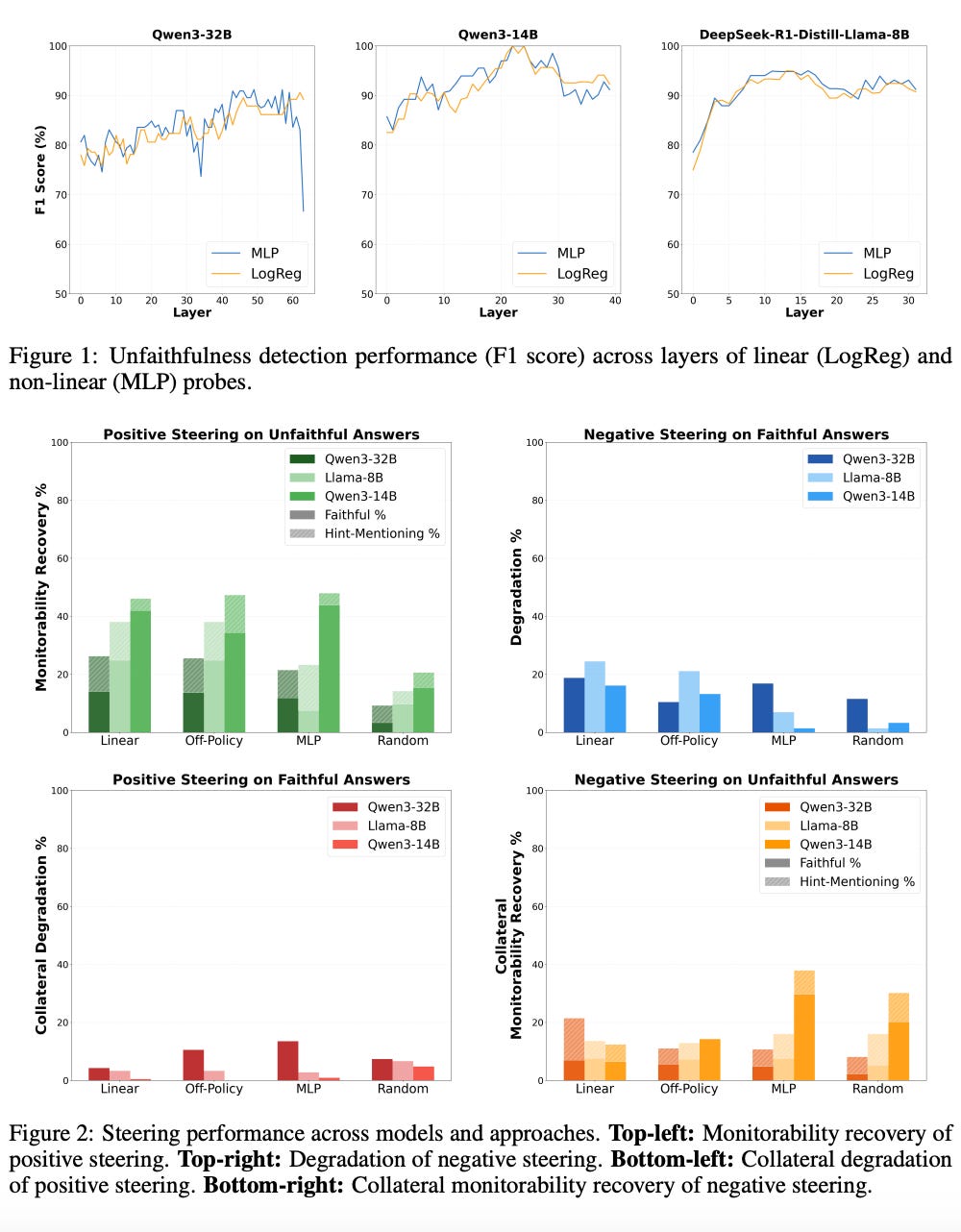
The paper has been accepted as an oral presentation at ICLR 2026 and Gio is looking for funders and collaborators to take it forward.
We’ll have more to say on future grant waves and how you can get involved in the coming weeks. The best way to keep up to ensure you don’t miss any opportunities to share your work or ideas is to subscribe below.
Cosmos Institute is the Academy for Philosopher-Builders, technologists building AI for human flourishing. We run fellowships, fund AI prototypes, and host seminars with institutions like Oxford, Aspen Institute, and Liberty Fund.
Two of these projects converge with structural diagnostics that have names.
Replication Radar is detecting capital-epistemic feedback loops at the field level. Citation rings, author-network clustering, institutional monoculture, retraction non-propagation: each is a location where the entity whose claims are being evaluated benefits from the claims being accepted, and the evaluation process structurally produces validation regardless of evidence-state. The structural name for this is the Collider Conjecture. Karty's signals are the operational fingerprints of the conjecture: the loop that never returns to whether the original finding had merit. Moving from papers to concepts (theories, effects, methodological assumptions) is the right next step because the collider operates at the concept level, not the paper level. The paper is one node; the concept is the loop.
https://metacortexdynamics.substack.com/p/the-collider-conjecture
Batra's latent reasoning work is discovering implicit operator-deployment in model internals. Her eight reasoning stages (planning, computation, verification, answer emission) are structural operations the framework names as specific operators: planning is IF/THEN plus FOR-WHAT, computation is operator-chain execution, verification is witness-probing (does the output match its derivation chain), answer emission is commitment (MUST). The latent reasoning policy she detects is the model entering and maintaining operator-deployment modes without them having been named as such. The steering vectors that raise performance on hard problems are working because they push the model into operator-deployment regimes it could not reliably enter on its own.
Constitutive Geometric Projection: https://doi.org/10.5281/zenodo.20171365
Good stuff. (I think.) What does Richard Sutton think? And while some if these labels may be supportable, many sound like they are there products of Monty Python thinking.