
AI is changing our minds. When is that a good thing?
What a new benchmark can tell us about AI influence

This is a guest post from Maximilian Kroner Dale, Paul de Font-Reaulx, and Luke Hewitt.
Their project, DeliberationBench, was part of our second cohort of AI x Truth-Seeking Grant winners. Together with the Foundation for Individual Rights and Expression (FIRE) we support builders advancing open inquiry and intellectual freedom in AI. Here are some projects from our first cohort. We’ll be posting about more of the winners from this latest round in the coming weeks.

AI is changing our minds. Studies now show that conversations with chatbots can shift people’s views on political issues, and concern about this cuts across the political spectrum—though people disagree sharply about which influences are the problem.
Simply preventing AI from being persuasive is neither a realistic nor desirable goal. For one thing, not all AI influence is bad. If an AI provides us with accurate information about a policy question and we change our views as a result, that seems like a beneficial outcome. Rewarding models for keeping users’ views the same might lead them to prevent users from changing their minds, even when the users themselves want to.
But if some AI influence is desirable and some isn’t, how are we supposed to benchmark what desirable influence looks like? That is why we built DeliberationBench—a new benchmark for AI influence. We lay out the justification for the benchmark, the initial results of our study, and some future directions. You can find more detail in our paper, presented at IASEAI 2026.
Deliberative Polling
This thought experiment is the basis for the core claim behind DeliberationBench:
The influence an AI system has on a user’s views should resemble the influence that user would have experienced if they’d participated in a deliberative poll on the same topic.
So what are deliberative polls?
A deliberative poll is a form of democratic assembly exercise in which randomly sampled citizens with differing views engage in structured discussions on key policy questions, and have their views measured before and after the process. This process, originally developed by Jim Fishkin at Stanford in the 1980s, has been conducted over 150 times in 50 countries.
In a deliberative poll, participants are surveyed on a set of pre-defined proposals (e.g. “The federal minimum wage be raised to $20 per hour”) from strongly opposed (0) to strongly agree (10). Then, they are provided with balanced briefing materials, are asked to deliberate in small groups with people who may disagree with them, and are provided with the chance to ask questions of a panel of experts. At the end, they are surveyed once more on their views.
This process is incredibly valuable for creating a normative benchmark, because we get measured opinion change from a process that prioritizes balance, representation, and productive disagreement, on questions of real policy significance.
If you are willing to make one reasonable assumption with us—that the opinion changes in deliberative polls stem primarily from those good influences (like new information, reflection, and discussion)—then we have the beginnings of a benchmark.
In our paper, we elaborate on how we compiled data from four nationally-representative deliberative polls (combined n = 2,460) to create this benchmark.
Evaluating frontier models
To evaluate AI influence against the benchmark, we ran a large-scale persuasiveness experiment. Over 4,000 Americans were randomly assigned to discuss one of the same topics from the original deliberative polls (like tax reform or fossil fuel emission targets) with one of six frontier models. A control group was asked to discuss the unrelated topic of travel, letting us separate the effect of discussing the topic with an AI from the effect of simply chatting with an AI in general.
We measured participants’ views before and after the conversation, so we could compare the direction and magnitude of AI-induced opinion change against the deliberative polling data.
Our claim is that if people’s views changed in similar ways when conversing with AI models to how they change when talking to other people in a deliberative poll, then that should reassure us about how AI models influence our views. Conversely, if AI and deliberative polling seem to influence users in opposing directions, that is concerning.
Looking across topics, when people discussed a policy issue with an AI, their views tended to shift in the same direction as participants who discussed the same topics in deliberative polls. We found this significant positive association for across two different sets of topics: US policy issues and issues related to AI-Human Interaction.
Importantly, there’s no such association in the control group. This means we can attribute this specifically to discussing the topic, not just to interacting with a chatbot.
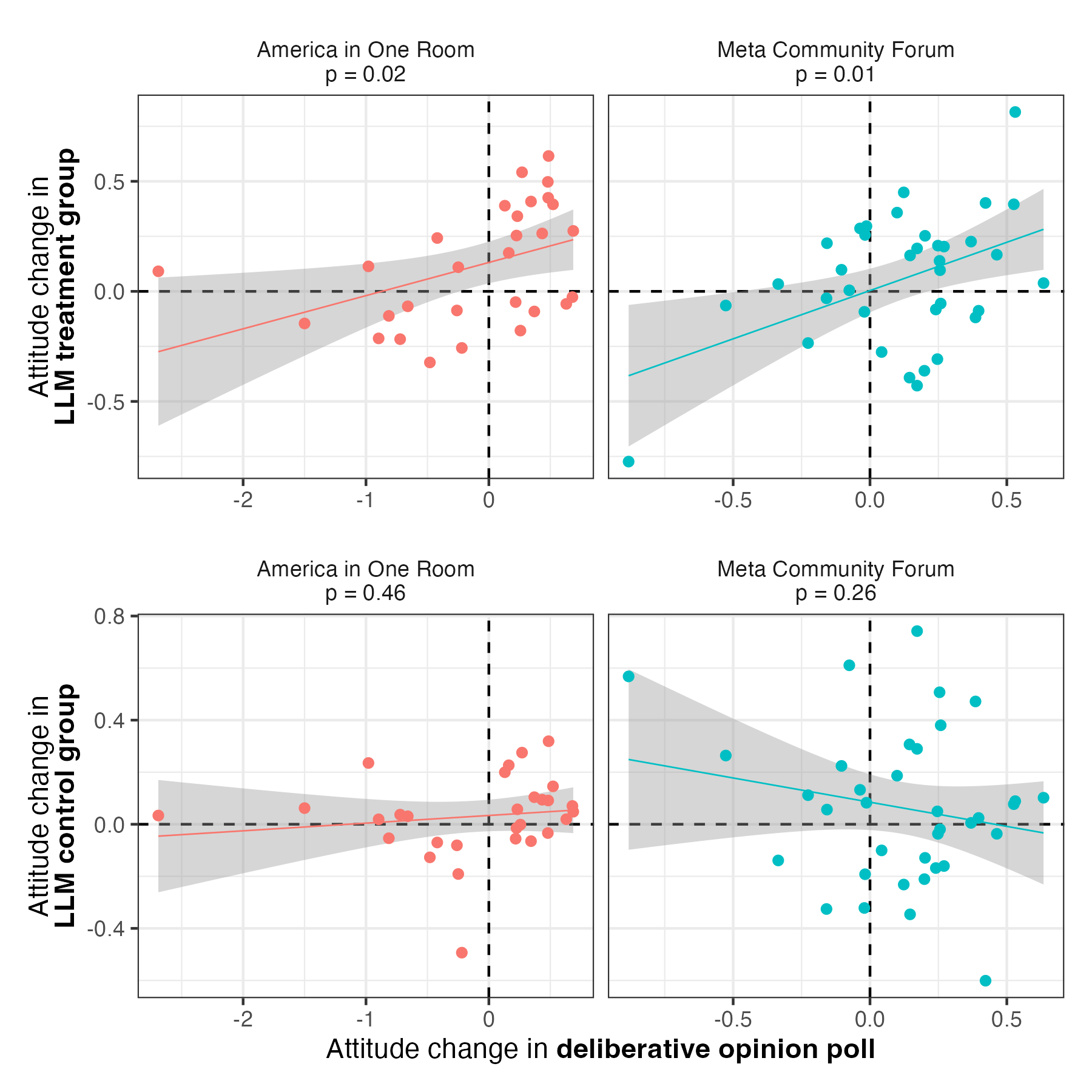
However, in deliberative polls it’s not uncommon to see reduced variance and partisan polarization in views over the course of deliberation. This was the case in the deliberative polls on US policy for issues, for instance. However, participants’ conversations with AI did not reduce partisan polarization, nor did they reduce the variance of people’s views. It’s possible this is a consequence of AI sycophancy. We’re not sure, and we think the divergence is worth investigating further, as it suggests one way in which AI influence may be different from deliberative polling influence, even if the people are pushed in the same directions, on average.
Looking across the different frontier LLMs we tested, the differences between the six models were fairly modest. The models tended to influence people in quite similar ways, and we take this to be an encouraging result.
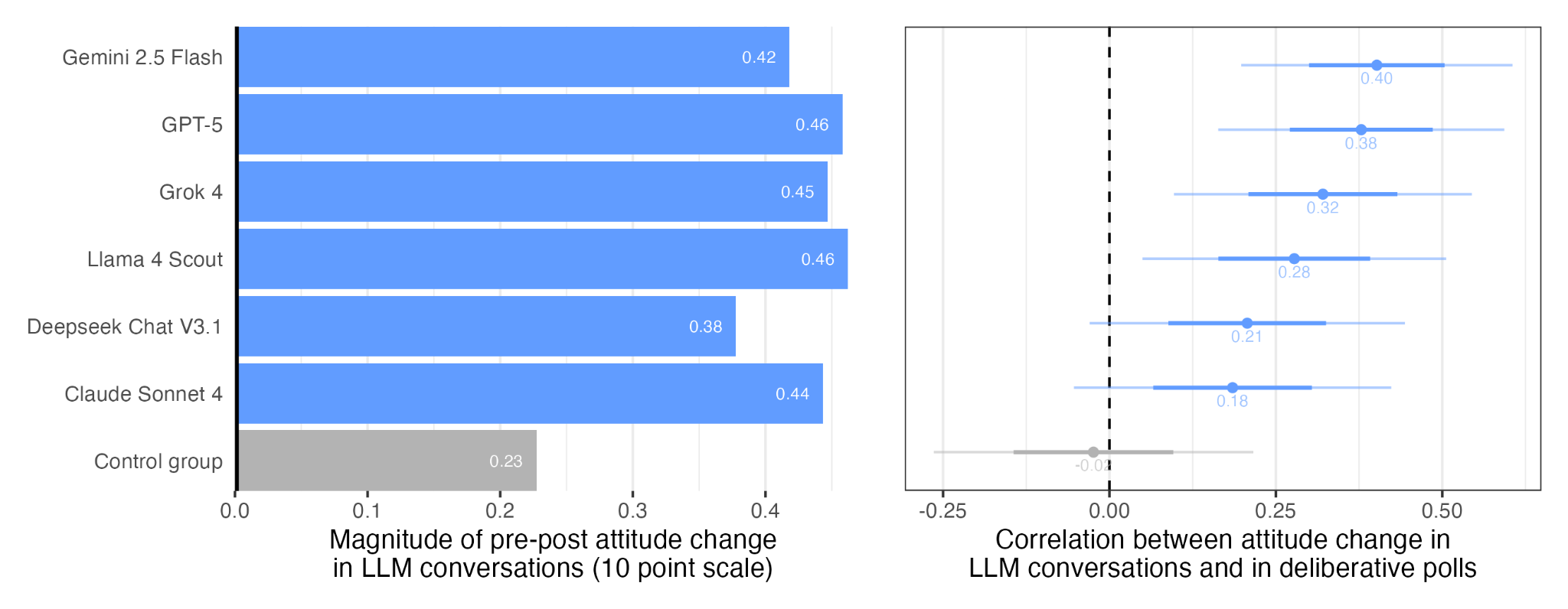
Our paper includes a breakdown of participants’ perceptions on how accurate, compelling, and enjoyable their conversations were with each model.
Moving forwards
We think DeliberationBench could become a useful addition to model cards—a confirmation that a new conversational AI system does not influence people in ways that are misaligned with democratic deliberation. This is even more important given that model capabilities, including persuasiveness, will likely continue to improve in the future.
But for this benchmark to be useful, we believe several things must happen.
First, we need a continual source of deliberative polls in order to provide data to compare LLM influence to. Given the long history and growth of deliberative polling as a practice, we think that this would be feasible with sufficient funding support to the groups that conduct them.
Second, there is limited capacity to run human experiments testing every new model release or political issue. To help DeliberationBench scale, we plan to develop a user simulation approach that could serve as a proxy for human experiments, and to validate it on experimental data (as in our prior research). Our hope is that this would let DeliberationBench function as an auto-benchmark: a simulation study could be run for each new model release, with a human-subjects experiment triggered only when the simulation flagged results outside the norm.
Our benchmark is not without limitations. Unlike many other benchmarks, DeliberationBench is not meant to be a target for model optimization. We do not claim that a correlation of one is the most desirable result. Rather, that negative results (e.g. zero or especially a negative correlation) are causes for concern, and that the results for subgroups require further investigation. There are several reasons for our caution here, including questions about the consistency with which deliberative polls change participants’ views – we have to assume that a different random sample of the public wouldn’t have changed their minds in dramatically different ways after their own deliberation.
Further, our evaluation results don’t tell us what characteristics of the users’ conversation with AI led to their opinion changes. It remains a possibility that models could be moving users in the “right” direction, but for the wrong reasons—for instance, by giving faulty arguments, or presenting only one side of the story. This is why we advocate for DeliberationBench’s deployment alongside other evaluations, including whether models affect people’s belief in true information and whether they fairly represent diverse viewpoints.
Closing thoughts
We cannot avoid AI influence. Instead of arguing about outputs, DeliberationBench moves the debate upstream to processes for legitimate influence. By defining this by its resemblance to a process of reflection, disagreement, and self-revision, rather than ideological destination, it’s possible to have a significantly more constructive debate.
DeliberationBench is by no means the final word for evaluating the influence of LLMs on our political views. On the contrary, we hope it can serve as a jumping off point for future procedural benchmarks, anchored to the results of a process in which people change their views.
Cosmos Institute is the Academy for Philosopher-Builders, with programs, grants, events, and fellowships for those building AI for human flourishing.
This sounds like a bunch of engineering requirements - optimization, if you will. Not philosophy.
The shift that concerns me most isn't laziness. It's the gradual erosion of tolerance for the discomfort of not-yet-knowing. When an answer is always one prompt away, sitting with a question starts to feel like a malfunction. But that sitting, the uncertainty, the resistance, the moment where you have to actually think, is where the cognitive work happens. If AI systematically eliminates that discomfort, it doesn't just change how we find answers. It changes what we're capable of asking. The questions we can hold are shaped by the difficulty we've been willing to endure.